Appearance
报名
准考证打印
考试时间
2023年度计算机技术与软件专业技术资格(水平)考试工作计划
2023 年 11 月 4 日(周六)
上午 9:00-11:30 : 基础知识
下午 14:00-16:30 : 应用技术
通过要求
新的:
45 + / 75

考核内容
- 计算机相关基础知识;
- 常用数据结构和常用算法;
- C程序设计语言,以及C++、Java中的一种程序设计语言
- 软件工程、软件过程改进从事软件设计与开发工作的中级技术人员。 和软件开发项目管理的基础知识;软件设计的 方法和技术。
岗位描述
从事软件设计与开发工作的中级技术人员
软件设计师考试说明
1.考试要求:
(1)掌握数据表示、算术和逻辑运算;
(2)掌握相关的应用数学、离散数学的基础知识;
(3)掌握计算机体系结构以及各主要部件的性能和基本工作原理;
(4)掌握操作系统、程序设计语言的基础知识,了解编译程序的基本知识;
(5)熟练掌握常用数据结构和常用算法;
(6)熟悉数据库、网络和多媒体的基础知识;
(7)掌握C程序设计语言,以及C++、Java、Visual Basic、Visual C++中的一种程序设计语言;
(8)熟悉软件工程、软件过程改进和软件开发项目管理的基础知识;
(9)熟练掌握软件设计的方法和技术;
(10)掌握常用信息技术标准、安全性,以及有关法律、法规的基本知识;
(11)了解信息化、计算机应用的基础知识;
(12)正确阅读和理解计算机领域的英文资料。
2.通过本考试的合格人员能根据软件开发项目管理和软件工程的要求,按照系统总体设计规格说明书进行软件设计,编写程序设计规格说明书等相应的文档;组织和指导程序员编写、调试程序,并对软件进行优化和集成测试,开发出符合系统总体设计要求的高质量软件;具有工程师的实际工作能力和业务水平。
3.本考试设置的科目包括:
(1)计算机与软件工程知识,考试时间为150分钟,笔试,选择题;
(2)软件设计,考试时间为150分钟,笔试,问答题。
题目布局
上午题
复习顺序
推荐:
- 中等难度,高分值(32 分)
- 数据结构(上): 5分左右(上+下一共)
- 数据结构(下): 5分左右(上+下一共)
- 软件工程(上): 10分左右(上+下一共)
- 软件工程(下): 10分左右(上+下一共)
- 操作系统: 固定6分
- 数据库: 固定6分
- 程序设计语言: 固定6分
- 低难度,中等分值(20 分)
- 计算机系统: 5~6分
- 信息安全: 5分左右
- 计算机网络: 固定5分
- 设计模式: 固定4分
- 算法: 4~5分
- 低难度,低分值(15 分)
- 面向对象: 3~4分
- UML: 3~4分
- 结构化开发: 3~4分
- 知识产权: 2~3分
- 高难度,低分值 (如果时间允许)
- 此部分视个人情况和剩余时间进行选择性复习。
难易顺序排序
| 序号 | 主题 | 分数 |
|---|---|---|
| 1 | 计算机系统 | 5.5 |
| 2 | 程序设计语言 | 6 |
| 3 | 知识产权 | 2.5 |
| 4 | 数据库 | 6 |
| 5 | 面向对象 | 3.5 |
| 6 | UML | 3.5 |
| 7 | 设计模式 | 4 |
| 8 | 操作系统 | 6 |
| 9 | 结构化开发 | 3.5 |
| 10 | 软件工程 | 20 |
| 11 | 信息安全 | 5 |
| 12 | 计算机网络 | 5 |
| 13 | 数据结构 | 10 |
| 14 | 算法 | 4.5 |
分值顺序排序
上午题 - 分值顺序(从高到低)
| 序号 | 主题 | 分数 |
|---|---|---|
| 1 | 软件工程 | 10 |
| 2 | 数据结构 | 5 |
| 3 | 程序设计语言 | 6 |
| 4 | 数据库 | 6 |
| 5 | 操作系统 | 6 |
| 6 | 计算机系统 | 5.5 |
| 7 | 信息安全 | 5 |
| 8 | 计算机网络 | 5 |
| 9 | 算法 | 4.5 |
| 10 | 设计模式 | 4 |
| 11 | 面向对象 | 3.5 |
| 12 | UML | 3.5 |
| 13 | 结构化开发 | 3.5 |
| 14 | 知识产权 | 2.5 |
章节
软件工程
Thu Nov 2 17:42, 2023
能力成熟度模型(CMM)
- 初始级:软件开发过程很混乱,成功全靠个人努力。
- 可重复级:有基本的项目管理,能重复之前的成功。
- 已定义级:软件开发过程已标准化,所有项目都按照这个标准执行。
- 已管理级:有明确的质量标准,团队能控制软件质量。
- 优化级:通过持续分析和改进,让软件开发过程不断进步。
能力成熟度模型集成(CMMI)
阶段式模型:看组织的成熟度,有5个级别:
- 初始的:过程混乱
- 已管理的:过程被项目管理
- 已定义的:过程被组织管理
- 定量管理的:过程被度量和控制
- 优化的:专注于过程改进
连续性模型:
- CL0(未完成的):过程域未执行或未达成所有目标
- CL1(已执行的):过程将输入转换为输出,实现特定目标
- CL2(已管理的):过程得到管理和制度化,遵循文档化的计划和过程描述
- CL3(已定义的):过程根据组织的剪裁指南从标准过程集中剪裁,收集过程资产和度量,用于未来改进
- CL4(定量管理的):使用测量和质量保证控制和改进过程,建立质量和过程执行的定量目标
- CL5(优化的):使用量化手段改变和优化过程,满足客户要求和持续改进计划的效能
模型
瀑布模型:由于其阶段性的流程如瀑布般一级级向下流动而得名。适合于软件需求很明确的软件项目的模型。缺乏灵活性,特别是无法解决软件需求不明确的问题。
增量模型:逐步增加功能以完成系统。第 1 个增量往往是核心的产品。优点:第一个可交付版本所需要的成本和时间很少;开发由增量表示的小系统所承担的风险不大

演化/原型模型:通过不断制作和改进原型来演化出最终系统。适合用户需求不清、需求经常变化、系统规模不大也不复杂。
螺旋模型:其迭代的过程形似螺旋,强调风险分析。适用于庞大、复杂并且具有高风险的系统。需要开发人员具有相当丰富的风险评估经验和专门知识。另外,过多的选代次数会增加开发成本,延迟提交时间
喷泉模型:体现了开发活动的重叠和迭代,像喷泉的水流循环往复。喷泉模型的各个阶段没有明显的界线,开发人员可以同步进行。以用户需求为动力,以对象作为驱动的模型,适合于面向对象的开发方法。
统一过程(UP)模型:统一了多种最佳实践和过程框架。
敏捷方法
- 极限编程( XP )
- 4大价值观:沟通、简单性、反馈和勇气。
- 5个原则:快速反馈、简单性假设、逐步修改、提倡更改和优质工作。
- 12个最佳实践:计划游戏、小型发布、隐喻、简单设计、测试先行、重构、结队编程、集体代码所有制、持续集成、每周工作40个小时、现场客户和编码标准。
- 水晶法(Crystal)
- 核心观念:每个项目需要独特的策略、约定和方法论;人对软件质量有重要影响。
- 并列争求法(Scrum)
- 特点:30天一个“冲刺”,按需求优先级实现产品,自组织和自治的小组并行实现产品。
- 自适应软件开发(ASD)
- 6个基本原则:有指导使命;特征为客户价值关键;等待和“重做”关键;变化为实际调整;定时交付;包含风险。根据需求的变化及时调整开发过程
- 极限编程( XP )
软件需求
- 功能需求:考虑系统需要完成什么任务,什么时候完成,以及如何在未来修改或更新系统。
性能需求:关注软件的技术表现,比如多快运行,反应速度如何,能处理多少数据。
数据需求:考虑系统需要处理什么样的数据,数据怎样进出系统,保持多久,以及需要多大的准确度和精度。
系统设计
概要设计:
- 将一个复杂的系统按功能划分成模块
- 编写概要设计文档
详细设计:
对每个模块进行详细的算法设计
对模块内的数据结构进行设计
对数据库进行物理设计
其他设计
① 代码设计。为了提高数据的输入、 库中某些数据项的值要进行代码设计。
② 输入/输出格式设计。
③ 用户界面设计。
编写详细设计说明书。
评审
TODO:跳过,需要回看
操作系统
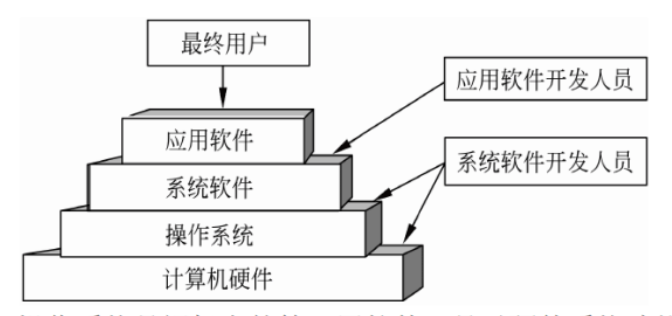
- 前趋图
- 信号量(Semaphore)
- P操作:用于申请资源
- V操作:用于释放资源
- 执行完进行 V 操作释放资源,执行前进行 P 操作申请资源
- 信号量,从左到右,从上到下
- 执行前:P,看箭头所表示的信号量。

Fri Nov 3 23:07, 2023: 看不动了,睡觉吧。
数据库
关系模式 - 类似 Excel 表格
三级模式:
外模式 - 视图,用户看得到的
模式 - 基本表
内模式 - 存储文件
模式映像
外模式 - (外模式/模式映像 - 数据的逻辑独立性) - 模式 - (模式/内模式映像 - 数据的物理独立性) - 内模式
队列
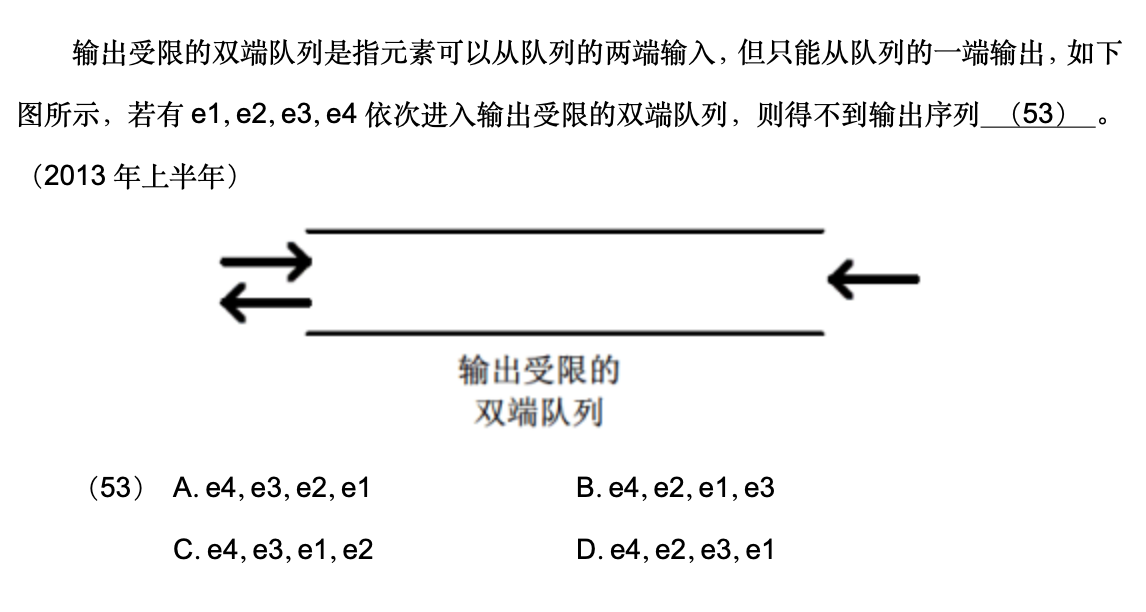
💡只考虑输入,看怎么输入可以得到下面的选项
程序设计语言
Mon Oct 30 23:52, 2023 结束
编译、解释程序的翻译
编译方式:词法分析、语法分析、语义分析、中间代码生成(可省略)、代码优化(可省略)、目标代码生成
解释方式:词法分析、语法分析、语义分析
按顺序!
词法、语法、语义分析与目标代码生成
可能考:每个阶段的作用
词法分析:
输入:源程序
输出:记号流
作用:将程序的字符序列转换为记号(tokens)序列。例如,它会识别
int,main,(,),{,},=等为不同的记号,并为每个记号分配类型如关键字、标识符、运算符等。语法分析
输入:记号流
输出:语法树/分析树
作用:检查程序的结构是否符合语言的语法规定。例如,它会检查
int a = 5;是否是一个合法的变量声明语句。语义分析
输入:语法树/分析树
作用:类型匹配和类型转换。例如,它会检查
int b = a + 10;中a的类型与10的类型是否兼容,以及b的类型是否与表达式a + 10的类型匹配。目标代码生成:
与具体的机器密切相关
寄存器在此分配
中间代码
形式:后缀式(没有前缀式)、三地址码(没有四地址码)、三元式、四元式和树(图)
不依赖具体的机器。有利于进行与机器无关的优化处理和提高编译程序的可移植性。
正规式与正规集(其实就是正则表达式)
正规自动机
从起点(不知道从哪里来的箭头)到终点(两个圈)经过的路径的值

⚠️ 确定性有限自动机:对于每个可能的输入符号,都只有一个唯一的转换路径;
非确定性有限自动机:多种转换路径。
M1 中 A 对于同一个 0 可以有不同的路径。
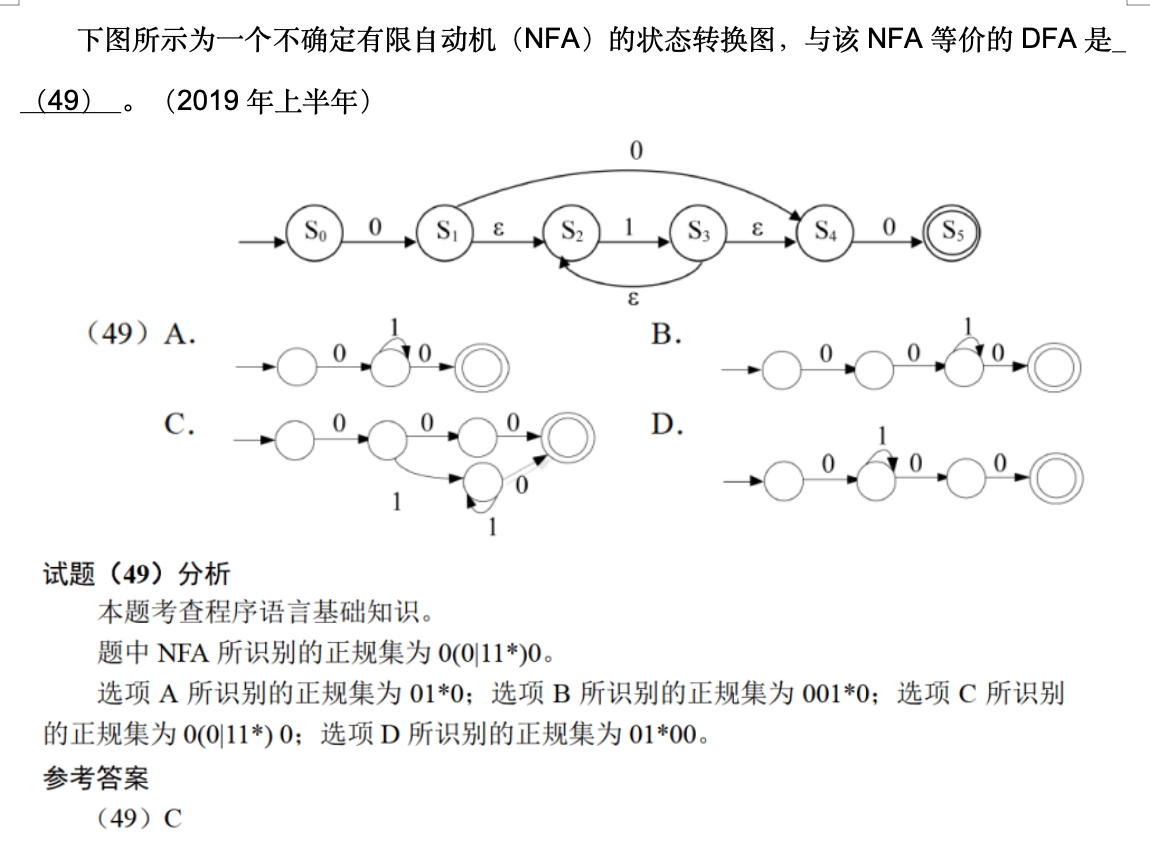
⚠️:
ε这个符号可以看成直接通过上下文无关文法
从S出发推导的、仅包含T中符号的符号串
计算机系统
Wed Nov 1 22:28, 2023
运算器与控制器
运算器组件:
| 部件名称 | 缩写 | 描述 |
|---|---|---|
| 算术逻辑单元 | ALU | 处理数据,对数据进行算数运算和逻辑运算 |
| 累加寄存器 | AC | 为算术逻辑单元ALU提供数据并暂存运算结果 |
| 数据缓冲寄存器 | DR | 作为CPU和内存、外部设备之间数据传送的中转站 |
| 状态条件寄存器 | PSW | 保存由算数指令和逻辑指令运行或测试的结果建立的各种条件码内容 |
控制器组件:
| 部件名称 | 缩写 | 描述 |
|---|---|---|
| 指令寄存器 | IR | 保存当前CPU执行的指令(地址码+操作码: 1+2 ,1、2为地址码,+为操作码)。 |
| 程序计数器 | PC | 初始时保存程序第一条指令的地址,执行指令时,CPU自动修改PC的内容对PC加1 |
| 地址寄存器 | AR | 保存当前CPU所访问的内存单元的地址 |
| 指令译码器 | ID | 根据指令寄存器(IR)的内容产生各种微操作指令。对指令中的操作码字段进行分析解释,识别该指令规定的操作 |
过程:
- 指令取得:
- 程序计数器 (PC) 指向内存中的下一条要执行的指令的地址。
- 该指令被加载到 指令寄存器 (IR) 中。
- 指令解码:
- 指令译码器 (ID) 解析 指令寄存器 (IR) 中的指令,确定需要执行的操作和操作数的位置。
- 操作数获取:
- 如果需要,CPU 从内存或其他寄存器中获取操作数。操作数可能会被加载到 数据缓冲寄存器 (DR) 或 累加寄存器 (AC) 中。
- 执行:
- 算术逻辑单元 (ALU) 根据指令执行相应的算术或逻辑运算。
- 运算结果可能暂时存储在 累加寄存器 (AC) 中。
- 结果存储:
- 结果被写回内存或保存在其他寄存器中,如 累加寄存器 (AC)。
- 状态更新:
- 根据运算结果,状态条件寄存器 (PSW) 更新,以反映运算的结果状态(例如,溢出、零或负状态)。
- 地址更新:
- 程序计数器 (PC) 更新,以指向下一条要执行的指令的地址,为下一个指令周期做好准备。
- 循环:
- 这个过程循环进行,直到程序执行完毕。

寄存器对于普通用户和程序员是透明的,意味着他们不能直接访问或修改这些寄存器的内容。通常情况下,这包括:
- 程序计数器 (PC): 它自动地指向下一条要执行的指令,通常不允许用户直接访问或修改。
- 指令寄存器 (IR): 它存储当前正在执行的指令,通常也不允许用户直接访问。
- 状态寄存器: 它存储了关于运算结果的状态信息,通常也不允许用户直接访问。
内存按字节编码
- 1KB = 2^10 = 1024
- bit :一个 bit 只有两种可能的值:0 或 1。8bit = 2^8 = 1024
- 一个地址表示一个字节也就是 8 位,8bit。66,560
10 <-> 16 进制转换
原、反、补、移码
Wed Nov 1 14:28, 2023
原码:最高位作为符号位,其余位表示数值。
反码:取反原码的非符号位(数值位)。
补码:反码 + 1。正数,补码与原码相同;负数,符号位保持不变,数值位取反后再加1。
移码:给每个数加上一个固定的偏移量(通常是2的n-1次方,其中n是位数)来表示有符号数。补码解决了反码的正负 0 问题,使得加法运算变得简单,并且只有一个零。几乎所有的现代计算机系统都使用补码来表示有符号整数。
通常用于浮点数的指数部分的表示,使得数的排序和比较变得简单。移码通过消除负数,简化了硬件的设计和数的处理。
补码的转换:
补码 -> 原码:补码 -1 后 取反数值位
数值范围

当机器字长为n时,补码和移码可表示 2^n 个数(0的表示有相同的编码)
原码和反码只能表示 2^n-1 个数(0的表示占了两个编码)
补充:
- 原码(Sign-Magnitude Representation):
- 在原码表示法中,最高位是符号位,其余位是数值位。
- 对于n位二进制数,最高位用于符号,剩下的
n-1位用于数值。- 最大的正数是符号位为0,数值位全部为1,即
0b0111...1(n-1个1),其十进制值是2^(n-1) - 1。- 最小的负数是符号位为1,数值位全部为0,即
0b1000...0,其十进制值是-(2^(n-1) - 1)。
- 反码(Ones' Complement):
- 反码和原码的表示范围相同,因为反码只是原码的位取反(除符号位外)。
- 补码(Twos' Complement):
- 补码的最大正数也是
2^(n-1) - 1,与原码和反码相同。- 但是,补码的最小负数是
-2^(n-1)。这是因为在补码中,最小负数的表示是符号位为1,其余位为0,即0b1000...0,其十进制值是-2^(n-1)。
- 移码(Excess-N or Biased Representation):
- 在移码中,数值通过添加一个偏移量来表示。通常的偏移量是
2^(n-1)。- 所以,二进制
0b0000...0(n个0)表示的十进制数是-2^(n-1),二进制0b1111...1(n个1)表示的十进制数是2^(n-1) - 1。
浮点数
计算时,小阶向大阶对齐,尾数右移

CISC & RISC
CISC(Complex Instruction Set Computer, 复杂指令集计算机)
RISC(Reduced Instruction Set Computer, 精简指令集计算机)
流水线技术
就是持续不断的输入直到这条线被塞满。
吞吐率:总指令数除以总执行时间 - 在单位时间内系统能够完成多少工作
速比: 加速比=不采用流水线的执行时间采用流水线的执行时间加速比=采用流水线的执行时间不采用流水线的执行时间
流水线操作周期:
- 流水线的操作周期由最长的操作时间决定。
流水线吞吐率: 吞吐率=1最长流水段操作时间吞吐率=最长流水段操作时间1
顺序执行时间: 顺序执行时间=(一条指令执行的时间)×(总指令数)顺序执行时间=(一条指令执行的时间)×(总指令数)
流水线执行时间: 流水线执行时间=(一条指令执行的时间)+(最长时间段)×(n−1)流水线执行时间=(一条指令执行的时间)+(最长时间段)×(n−1)
- 其中,nn 是总指令数。
连续输入 n*n* 条指令的吞吐率: 连续输入吞吐率=总指令数总指令数执行的时间连续输入吞吐率=总指令数执行的时间总指令数
存储器
Wed Nov 1 13:15, 2023
访问方式分类:
按地址访问的存储器:访问时根据地址来检索数据。
寻址方式分类:
- 随机存储器(Random Access Memory, RAM):允许在任何时间直接访问任何位置的数据。
- 顺序存储器(Sequential Access Memory):按顺序访问数据,例如磁带存储器。
- 直接存储器(Direct Access Memory):允许直接访问非顺序数据,但可能需要更多时间来定位数据。
按内容访问的存储器(例如,相联存储器 也称为内容寻址存储器或CAM,Content-Addressable Memory):访问时根据内容来检索数据。相联由来:根据内容进行数据检索的功能可以看作是一种“关联”或“相联”的行为,因为它将数据内容与存储器中的数据进行匹配或“关联”。
虚拟存储器:
- 组成:由主存储器(通常是DRAM)和辅助存储器(通常是硬盘)组成,以扩展可用的存储空间。
主要类型的RAM:
SRAM(静态随机存储器):构成缓存(Cache),不需要刷新,速度快,贵。
DRAM(动态随机存储器):构成主存,需要周期性刷新以保持信息。
其他:
EPROM(Erasable Programmable Read-Only Memory,可擦除可编程只读存储器):U盘
直接存储器:允许直接访问任何存储位置,但是寻址时间可能会因位置而异。
Cache
Wed Nov 1 21:08, 2023
- Cache与主存的地址映射由硬件自动完成
- 直接映射:固定关系,高冲突。 主存的每一块只能映像到 Cache 的一个特定的块中
- 全相联映射:低冲突,灵活关系,主存块可映射至任意Cache块,Cache满时需替换。
- 组相联映射:折中方案。
中断
Wed Nov 1 21:15, 2023
- 中断向量:提供中断服务程序的入口地址。使 CPU 在中断发生时能找到并执行相应的中断处理程序。
- 中断响应时间:从中断请求发出到系统开始处理该中断的时间间隔。
- 保存现场:保存现场是保留当前程序的执行状态,以便在中断处理完成后能够正确返回并继续执行原程序。
输入输出(IO)控制方式
Wed Nov 1 21:33, 2023
| 项目/方式 | 程序查询方式 | 中断驱动方式 | 直接存储器存取方式 (DMA) |
|---|---|---|---|
| CPU和I/O工作模式 | 串行,CPU轮询检查 | 并行,I/O设备通过中断通知CPU | 并行,仅在数据传输开始和结束时需要CPU干预 |
| CPU利用率 | 低,因为需要不断轮询 | 提高,因为只在中断时处理I/O | 提高,因为大部分I/O操作由DMA控制器处理 |
| 数据传输单位 | 一个字 | 一个字 | 一个块 |
| 数据传输方向 | 由CPU将数据放入内存 | 由CPU将数据放入内存 | 由外设直接将数据放入内存或相反 |
| 保护现场需求 | 需要 | 需要 | 不需要 |
| CPU干预频率 | 频繁,每次读/写都需要 | 中等,只在I/O操作完成时需要 | 低,只在传输开始和结束时需要 |
| 存储周期占用 | 无特殊说明 | 无特殊说明 | DMA传送一个数据占用一个存储周期 |
总线
1 分,有时间看。
加密
Wed Nov 1 22:02, 2023
- 公钥加密: A -> B, A 使用 B 的公钥加密。B 使用自己的私钥解密。
- 数字签名: A 用自己的私钥生成数字签名。B 用 A 的公钥验证。数字签名可证明不可伪造
- 数字证书:用CA机构的私钥签名。对真实性的保护
加密算法
- 公开密钥加密(非对称加密)
- RSA - 摘要签名
- 私钥加密(对称加密)
- DES - 56 位密钥对 64 位二进制数据块加密
- AES - 分组加密
- RC4, RC5, RC6
- 攻击
- 被动攻击:不破坏消息,如窃听。加密可防止。
- 主动攻击:更改消息。认证可帮助检测,但是不能防止。
系统可靠度 - 串并联计算
Wed Nov 1 22:27, 2023
- 串联:R1R2R3...Rn
- 并联:1-(1-R1)(1-R2)...(1-Rn)
太简单了
信息安全
Start: Wed Nov 1 22:32, 2023
End: Wed Nov 1 23:18, 2023
防火墙
内网 - DMZ(Demilitarized Zone) - 外网
防火墙类型 优点 缺点 包过滤防火墙 快速、低级别控制、透明性、基本数据包检查 不能防范高级攻击、不支持应用层协议、配置简单 应用代理网关防火墙 强大的安全性、彻底隔断内外网、应用层代理软件转发 配置困难、处理速度慢 状态检测技术防火墙 安全性与速度的平衡、活动连接状态跟踪 (这部分通常视具体实现和配置而定) DMZ 区存放的服务器
- 邮件服务器
- FTP 服务器
- WEB 服务器
透明:对用户和/或应用程序隐藏底层处理细节的特性

病毒
Wed Nov 1 22:55, 2023
- 特征:
- 传播性:能够自我复制并通过网络或其他方式传播到其他系统。
- 隐蔽性:通常会尽量隐藏自己的存在,避免被用户或安全软件发现。
- 感染性:能够感染其他文件或系统。
- 潜伏性:可能在一段时间内保持不活跃,直到某些条件被满足。
- 触发性:通常会有特定的触发条件,如日期、特定事件等。
- 破坏性:可能会删除文件、破坏系统或进行其他恶意活动。
- 类型:
- 蠕虫病毒(Worm):自我复制并能独立传播,不依赖于宿主文件。
- 特洛伊木马(Trojan):伪装为正常软件,但会在背后执行恶意操作。
- 后门病毒(Backdoor):创建系统后门,允许攻击者远程访问和控制受感染系统。
- 宏病毒(Macro):主要感染文本文档和电子表格,通过宏命令执行恶意操作。
- 木马软件:
- 冰河:一种常见的木马软件,可以控制受感染的系统。
- 蠕虫病毒:
- 欢乐时光、熊猫烧香、红色代码、爱虫病毒、震网:这些都是历史上著名的蠕虫病毒,它们通过不同的方式传播并对受感染的系统造成不同程度的破坏。
网络攻击
拒绝服务攻击(Dos攻击):目的是使计算机或网络无法提供正常的服务拒绝服务攻击是不断向计算机发起请求来实现的
重放攻击:攻击者发送一个目的主机已经接受过的报文来达到攻击目的攻击者利用网络监听或者其他方式盗取认证凭据,之后再重新发送给认证服务器。
主要用于身份认证过程,目的是破坏认证的正确性。
Sql注入攻击:没有对用户输入数据的合法性进行判断,使应用程序存在安全隐患。获取数据库的权限,就可获取用户账号和口令信息,以及对某些数据修改等。
入侵检测技术:专家系统、模型检测、简单匹配
网络安全
| 协议/技术 | 描述 |
|---|---|
| SSL(443端口) | 由Netscape于1994年开发的传输层安全协议 |
| TLS | 建立在SSL 3.0之上的传输层安全协议 |
| SSH | 远程登录和网络服务,防止远程管理过程中的信息泄露 |
| HTTPS | 使用SSL加密 |
| MIME(Multipurpose Internet Mail Extensions) | 多用途互联网邮件扩展类型 |
| PGP(Pretty Good Privacy) | 基于RSA的邮件加密软件,邮件保密和数字签名 |
| IGMP | Internet Group Management Protocol, 用于组织IPv4网络上的多播组 |
| RFB(Remote Framebuffer) | 远程访问图形用户界面 |
计算机网络
1. 网络设备
物理层设备(不能隔离广播域和冲突域):中继器、集线器(多端口的中继器,不能自动寻址、可以检测发送冲突)
数据链路层设备(能隔离冲突域但是不能隔离广播域):网桥、交换机(多端口的网桥)
网络层设备:路由器
应用层设备:网关
冲突域是指一个网络区域内,如果两台设备在同一时刻发送数据,就会发生数据冲突的区域。
广播域是指一个网络区域内,一台设备发送的广播消息能被区域内所有设备接收的区域。
2. 协议簇
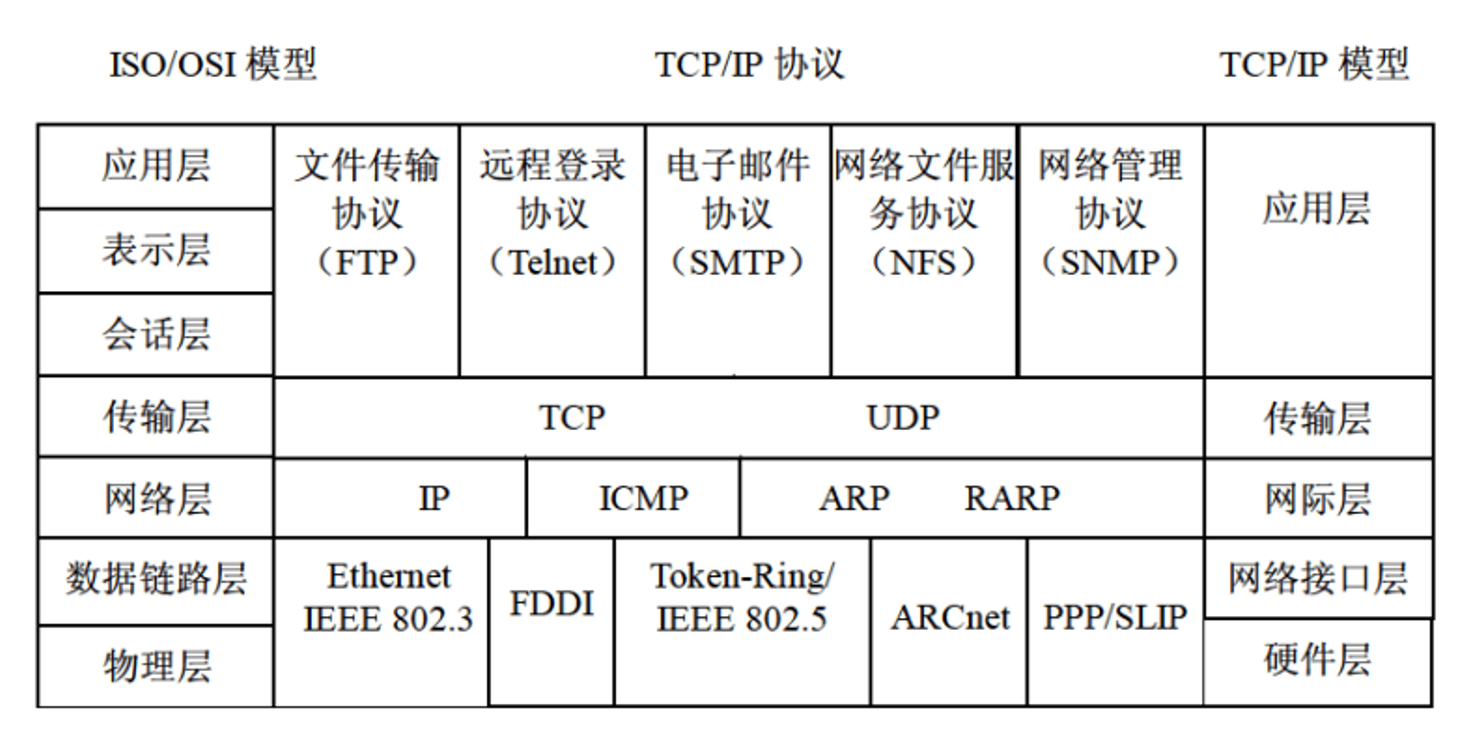
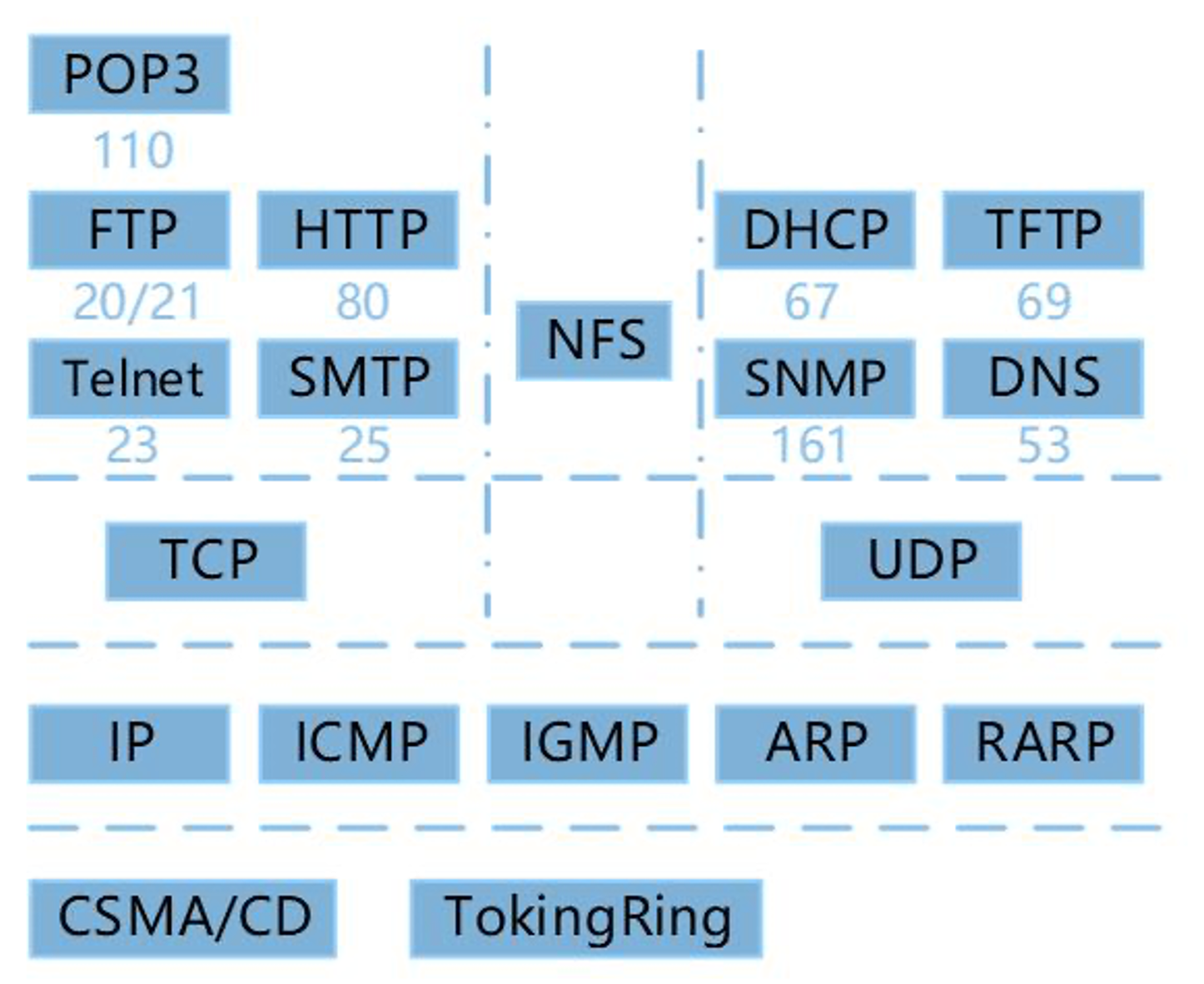
FTP 控制端口:21,上传端口:20
TCP、UDP 在传输层,IP 在网络层、ARP 网络层
邮件
发送邮件 - SMTP - 端口号:25
SMTP只能传输SACII码文本和文字附件,使用MIME邮件扩充协议,添加其他类型的附件。
接收邮件 - POP3 - 端口号:110
POP3基于C/S模式也就是Client/Server模式(客户端/服务器模式)
SMTP和POP3都使用TPC传输和接收邮件
ARP 便在局域网上以广播方式发送一个ARP 请求包。如果局域网上地址与某台计算机中的IP 地址相一致,那么该计算机便生成一个 ARP 应答信息,信息中包含对应的物理地址。
DHCP
- 通过 DHCP,当设备连接到网络时,它会自动从 DHCP 服务器获取配置信息,这样,网络管理员就不必手动配置每台计算机的网络设置,从而简化了网络管理,并确保了 IP 地址的有效利用和网络配置的一致性。以在设备离开网络后回收和重新分配,DHCP 也能提高 IP 地址的使用率。
DHCP客户端可以从DHCP服务器获得本机IP地址、DNS服务器地址、DHCP服务器地址和默认网关的地址等。
- Windows无效地址:169.254.X.X Linux无效地址:0.0.0.0
DNS域名查询的次序是:本地的hosts 文件一本地 DNS缓存一本地 DNS 服务器一根域名服务器。
IP地址和子网划分
Windows命令
- ipconfig/release:DHCP客户端手工释放IP地址
- ipconfig/flushdns:清除本地DNS缓存内容
- ipconfig/displaydns:显示本地DNS内容
- ipconfig/registerdns:DNS客户端手工向服务器进行注册
- ipconfig:显示所有网络适配器的IP地址、子网掩码和缺省网关值
- ipconfig/all:显示所有网络适配器的完整TCP/IP配置信息,包括DHCP服务是否已启动
- ipconfig/renew:DHCP客户端手工向服务器刷新请求(重新申请IP地址)
路由

- 纯IPv6节点能够与纯IPv4节点进行通信,通常需要使用协议转换技术
- 两个IPv6节点能够通过现有的IPv4网络进行通信,通常会使用隧道技术。
操作系统
- 线程不能和另一个线程共享资源
- 缓冲区:
- 单缓冲区:顺序执行
- 双缓冲区:类似流水线
设计模式
Thu Nov 2 12:59, 2023
分类
| 设计模式类别 | 名称 | 目的 |
|---|---|---|
| 创建型 | 单例、工厂方法、抽象工厂、建造者、原型 | 隐藏创建逻辑的方式 |
| 结构型 | 适配器、桥接、组合、装饰、外观、享元、代理 | 类和对象的组合 |
| 行为型 | 责任链、命令、解释器、迭代器、中介者、备忘录、观察者、状态、策略、模板方法、访问者 | 对象间的通信 |
类模式:
- 主要是通过继承来组织代码。关注类的结构和类之间的关系。
- 主要是通过继承来组合类,静态的在编译时刻确定。
对象模式:
- 通过对象的组合来组织代码。关注对象的组合或对象之间的通信。
- 主要是通过对象的组合或聚合来定义对象之间的关系,动态的在运行时刻确定。
简要介绍
创建型模式:
- 单例模式:确保一个类只有一个实例,并提供全局访问点。只允许创建一个实例,因此称为单例。
- 工厂方法模式:提供一个创建对象的方法,由子类决定实现哪一类,例如不同的工厂生产不同的商品。
- 抽象工厂模式:提供一个创建相关对象的接口,但不指定具体类,例如创建一系列相互关联的产品。
- 建造者模式:逐步构建一个复杂对象。例如构建一个汽车,需要多个步骤完成。
- 原型模式:通过拷贝现有对象来创建新对象。例如通过克隆来复制一个已存在的对象。
结构型模式:
- 适配器模式:允许不兼容的接口能够一起工作。就像现实生活中的适配器能使两个不同接口的设备连接一样,适配器模式能使不兼容的接口能够一起工作。
- 桥接模式:像桥一样连接了抽象和实现两个部分,使它们能独立变化而不影响对方。将抽象部分与实现部分分离。
- 组合模式:允许单个对象和组合对象统一处理。
- 装饰模式:在运行时动态给对象添加新功能。就像装饰物装饰房间一样。
- 外观模式:提供了一个统一的接口,来访问子系统中的一群接口。像建筑的外观为我们提供了简单的、一致的视图,外观模式为一组接口提供了一个统一的接口。
- 享元模式:减少创建对象的数量,以减少内存占用和计算开销。享元在汉语中意为轻量级,此模式旨在减少内存的使用。
- 代理模式:就像现实世界中的代理人代表你执行某些操作,代理模式中的代理对象为其他对象提供访问控制。
行为型模式:
- 责任链模式:像一个请求在链条上的传递,每个节点有责任决定处理或传递。
- 命令模式:将请求操作封装成命令对象,使得我们可以用不同的请求对客户进行参数化。
- 解释器模式:设计用于解释语言的解释器。
- 迭代器模式:如果你有一组对象,想逐个访问它们,但不想暴露它们的内部结构,可以使用迭代器模式。
- 中介者模式:通过中介者对象来减少系统组件之间的通信,简化依赖关系。将多对多依赖变成一对多。
- 备忘录模式:保存对象的某个状态,以便可以恢复。
- 观察者模式(Observer):允许对象监视另一对象的状态,类似于日常生活中的观察。当一个对象状态变化时,其所有依赖都会收到通知。你在网上订阅了某个商店的促销信息,当商店有促销时,它会给所有订阅了通知的人发送促销信息。在这个例子里,商店就是
Subject(目标),而订阅通知的人就是Observer(观察者)。商店有很多促销信息,对应不同的ConcreteSubject,而每个人(ConcreteObserver)选择订阅哪些促销信息。当商店发布新的促销信息时,所有订阅了这个促销信息的人都会收到通知。 - 状态模式(State):当你的对象的行为依赖于其状态,而你不想用大量的if-else语句时,可以使用状态模式。它允许你在对象的状态改变时,改变其行为。例如,一个电灯有开和关两种状态,行为(亮度)会随状态改变。
- 策略模式:允许从一系列策略中选择一种执行。定义一系列的算法,并将每一个算法封装起来,允许选择算法的策略,因此被称为策略模式。
- 模板方法模式:这个模式通过在父类中定义一个操作的框架,但将一些步骤的具体实现延迟到子类中完成。想象一个制作蛋糕的框架,步骤如混合、烘焙是固定的,但具体的配料和装饰可以变化。
- 访问者模式:如果你有一些对象,想在不修改它们的情况下添加新功能,可以使用访问者模式。它通过创建新的访问者类来实现新功能,而不是在原有类中添加代码。
面向对象
Thu Nov 2 14:17, 2023
类
| 类型 | 定义 | 示例 |
|---|---|---|
| 实体类 | 现实世界中真实的实体,如人、物等 | 人类、汽车类 |
| 接口类/边界类 | 提供与系统合作交互的方式,分为人和系统两大类 | 显示屏类、窗口类、Web 窗体类、对话框类、菜单类、列表框类等 |
| 控制类 | 控制活动流,充当协调者 | 活动控制器类、交易处理类等 |
对象和消息:对象 <--消息--> 对象
方法重载:在同一个类中,方法名相同但参数列表不同的方法,通过参数列表的不同来区分这些方法。
过载多态:(Overloading Polymorphism)是指在同一个类中可以有多个同名但参数列表不同的方法,根据传递给方法的参数类型和数量的不同,编译器会决定调用哪个方法。过载多态主要是在编译时确定,因此也被称为编译时多态或静态多态。
类(Class):定义了一种数据类型的蓝图,包括属性(数据成员)和方法(函数)。
对象(Object):类的实例,包含实际的数据和操作数据的方法。
封装(Encapsulation):将数据和操作数据的方法捆绑在一起,保护数据不被外界直接访问。
继承(Inheritance):允许创建基于现有类的新类,新类继承并可以扩展或修改现有类的属性和方法。
多态(Polymorphism):允许方法在多个子类中以不同的方式实现,提供一个通用的接口来访问这些方法。
- 参数多态:最纯的多态。通过使用泛型,你可以编写能处理多种数据类型的代码,例如数组或列表操作。想象你有一个能装任何东西的盒子,不管是苹果、香蕉还是书,你的盒子都能装。在编程中,泛型就像这个能装任何东西的盒子,你只需要一个盒子(代码),就能处理不同的东西(数据类型)。
- 包含多态:子类型化。子类可以替代父类。想象有个地方需要一个动物,但不管是猫、狗还是鸟都可以。在编程中,子类(比如猫、狗)能替代父类(动物)的位置,都能完成“叫”这个动作,但叫声不同。
- 过载多态:通过方法重载实现,即在同一个类里,有相同名称但参数不同的多个方法。
- 强制多态:通过类型转换,使得一个数据类型可以被视为另一个类型。例如,将一个整数转换为浮点数。
抽象(Abstraction):隐藏复杂性,只显示重要的信息。
接口(Interface)和实现(Implementation):定义操作的契约,而实现提供契约的具体逻辑。
静态、动态绑定
- 静态绑定(或早期绑定):在编译时,程序已经确定对象会调用哪个方法。方法的调用地址在编译时就已经确定了。
- 动态绑定(或晚期绑定):在运行时,根据对象的实际类型来决定调用哪个方法。方法的调用地址在运行时才确定。
- 静态绑定更快,但是动态绑定提供了更高的灵活性,使得多态成为可能。
面向对象设计原则
单一责任原则:强调一个类应只负责一项职责。
开放-封闭原则:强调软件实体应对扩展开放,对修改封闭。
里氏替换原则:由 Barbara Liskov 提出,强调子类型应可替换其父类型。
依赖倒置原则:强调依赖于抽象而非具体实现。
接口分离原则:强调接口的单一职责和精简性。
共同封闭原则:一个变化若对一个包产生影响,则将对该包中的所有类产生影响,而对于其他的包不造成任何影响。
共同重用原则:重用了包中的一个类,那么就要重用包中的所有类
面向对象分析与设计
- 面向对象分析 OOA 主要关注理解问题域,确定系统的功能和性能要求,识别关键对象并组织它们,同时描述对象间的交互和操作。
- 面向对象设计 OOD 则是将分析阶段得到的模型转化为具体的系统设计蓝图,考虑实现细节和执行环境的特点,以确保设计能够有效地实现所需功能。
举例:
面向对象分析(OOA):
- 认定对象: 图书(Book),用户(User),借书记录(BorrowRecord)
- 组织对象: 抽象成类,例如图书类(Book),用户类(User),借书记录类(BorrowRecord)
- 描述对象间的相互作用: 用户可借阅图书,每次借阅会生成一条借书记录
- 确定对象的操作: 用户可借书、还书,图书可被借出、被归还。
面向对象设计(OOD):
- 识别类及对象: 根据分析结果,已识别出图书类、用户类和借书记录类
- 确定对象的操作: 设计每个类的方法,如用户类的借书方法、还书方法;图书类的被借出方法、被归还方法等
- 描述对象间的相互作用: 设计类之间的关系,如用户和借书记录之间的关系,图书和借书记录之间的关系等
- 识别关系: 确定类之间的关联、继承和依赖关系
- 识别包: 将相关的类组织到不同的包(例如模型包、控制器包等)中以实现模块化设计
- 定义属性和服务: 为每个类定义详细的属性和方法,确定每个方法的实现逻辑。
UML
1. UML事物
| UML 构造块类别 | 事物 | 例子 |
|---|---|---|
| 结构事物 | 名词、模型的静态部分 | 类、接口、协作、用例、主动类、构件、制品、结点 |
| 行为事物 | 动词、模型的动态部分 | 交互、状态机、活动 |
| 分组事物 | 模型的组织部分 | 包 (最主要的分组事物) |
| 注释事物 | 模型的解释部分 | 注解 (用来描述、说明和标注模型的任何元素) |
2. UML关系
| 关系类型 | 说明 | 举例 |
|---|---|---|
| 依赖 | 一个类的方法操纵另一个类的对象 | 一个Driver类依赖于Car类 |
| 关联 | 类与类之间的长期关系 | 一个Student类关联一个School类 |
| 聚合 | "整体-部分"关系 | 一个Library类聚合多个Book类 |
| 组合 | 更强的"整体-部分"关系,整体没有则部分也消失 | 一个Company类组合多个Department类 |
| 继承 | 类与类之间的泛化关系,子类继承父类的特性和行为 | 一个Car类继承自Vehicle类 |
3. 关联多重度
多重度用来指定一个元素的实例可以与另一个元素的实例相关联的数量。
4. UML类图
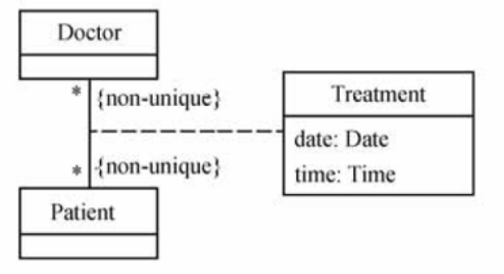
5. UML对象图
6. UML用例图
用例图说明参与者及其扮演的角色,可以是人、硬件或者其他系统可以扮演的角色,而非个人用户。
7. UML序列图
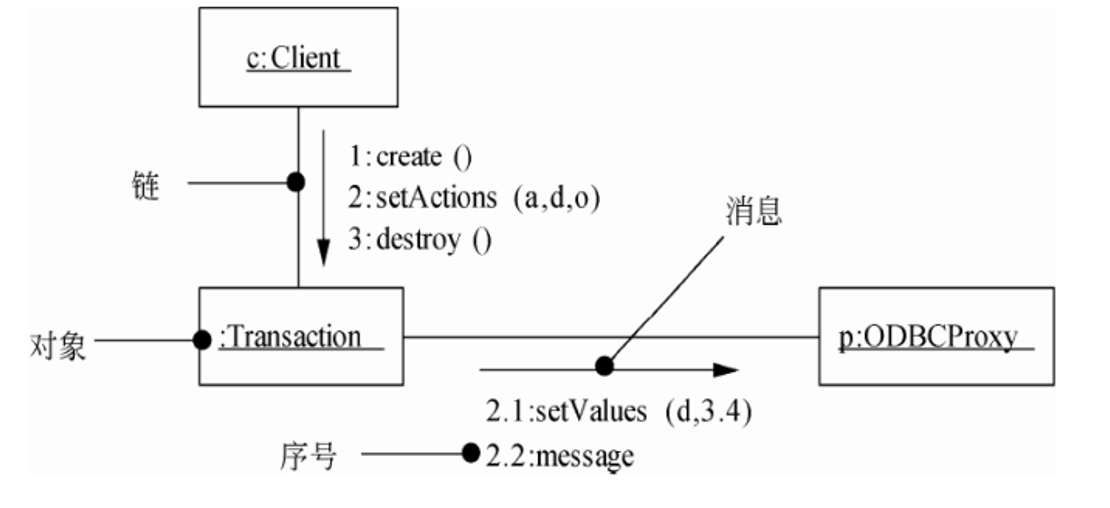
8. UML通信图
9. UML状态图
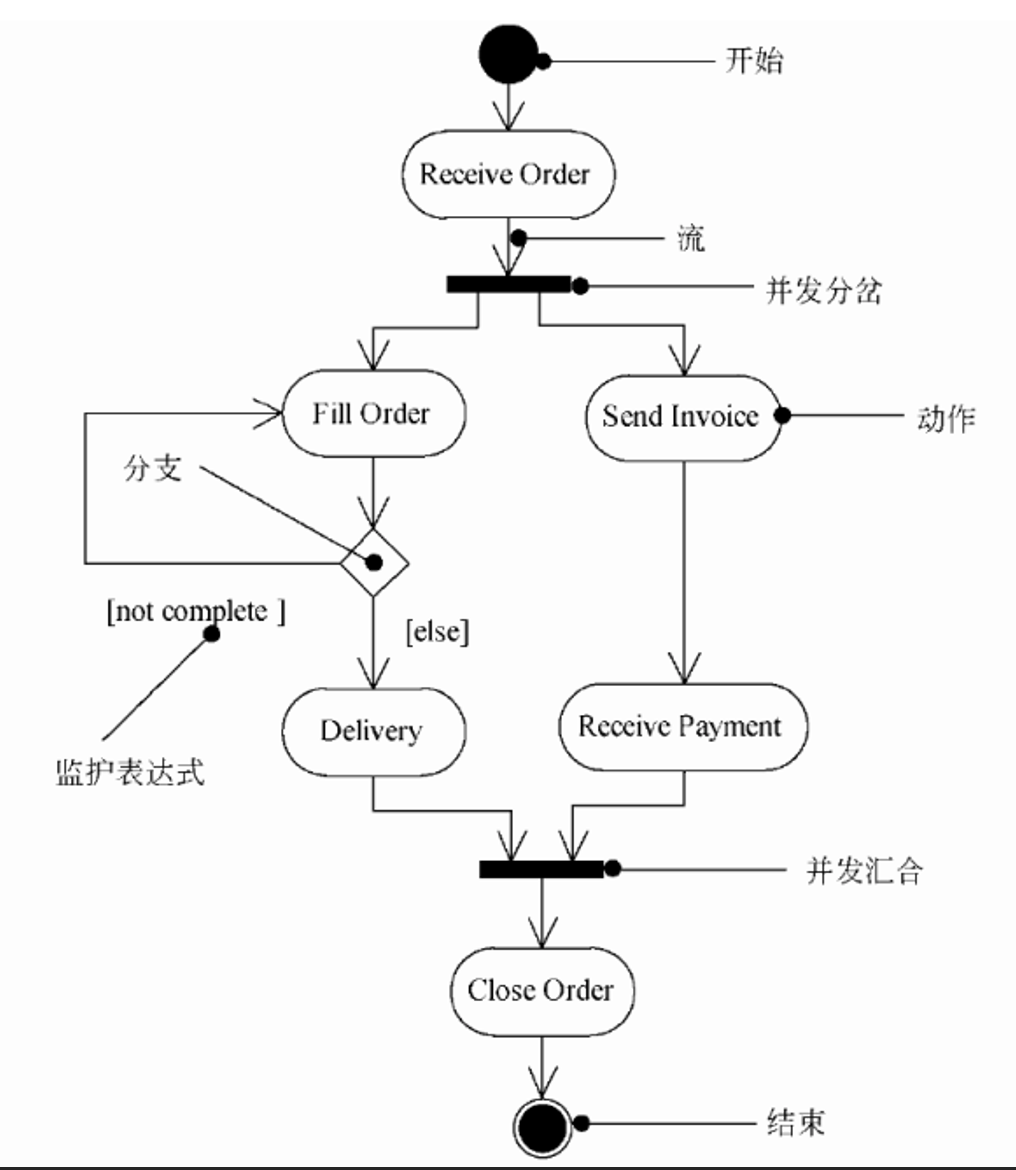
10. UML活动图
对一个复杂用例中的业务处理流程进行进一步建模的最佳工具是
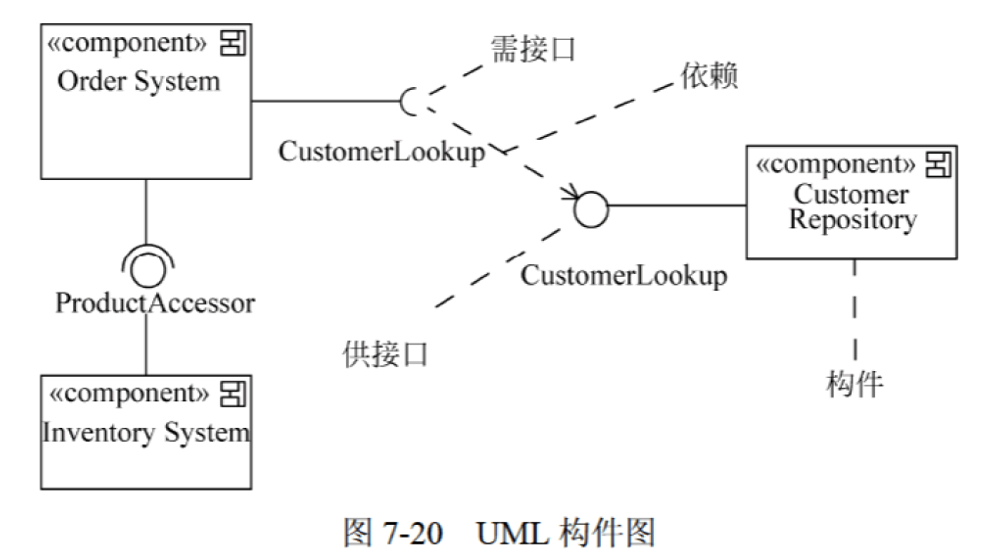
11. UML构件图(组件图)
12. UML部署图
展示交付系统的软件组件和硬件之间的关系
结构化开发
Fri Nov 3 00:37, 2023
- 特别适合于数据处理领域的项目。但是不适合解决大规模的、特别复杂的项目,而且难以适应需求的变化。
- 结构图的基本成分:模块、调用和数据。
1. 耦合 (Coupling) 与 内聚(Cohesion)
"高内聚,低耦合"。可以使系统更容易维护和扩展。
耦合 (Coupling): 描述了模块之间的依赖关系或交互程度。低耦合意味着模块之间的依赖较少,修改一个模块不太可能影响到其他模块。
内聚 (Cohesion): 描述了模块内部元素之间的相关程度。高内聚意味着模块内部的元素或功能紧密相关,形成一个统一的整体。

- 功能内聚: 一个函数只执行一项特定的任务,例如,
printText()函数仅仅打印文本。 - 顺序内聚: 函数按特定顺序执行一系列相关操作,例如,
processData()函数先验证数据,然后排序,最后显示。 - 通信内聚: 函数处理相同的数据结构或集合。所有操作都是围绕着相同的数据结构或集合来完成的,因此,它们通过数据“通信”来实现协作。例如,
manageUserData()处理用户数据的多个方面(获取、更新、验证)。 - 过程内聚: 函数执行一系列相关的操作,但不必按特定顺序,例如,
performOperations()函数可以执行加、减、乘、除等操作。 - 时间内聚: 函数在特定时间或条件下执行多个操作,例如,
morningRoutine()函数在早上执行一系列任务。 - 逻辑内聚: 函数根据传递的标志参数执行不同的操作,例如,
performAction(flag)根据flag值执行不同操作。 - 偶然内聚: 函数执行不相关的多个操作,没有明确的逻辑关系,例如,
miscellaneousActions()函数执行多种不相关的任务。
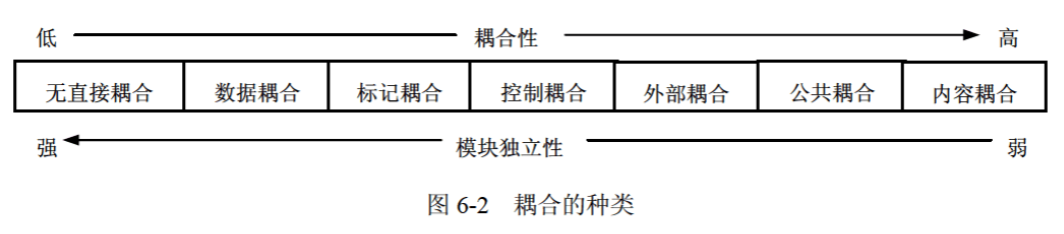
当讨论模块或系统组件之间的耦合时,可以将其想象成不同房间之间的门。
无直接耦合(No Direct Coupling):
- 两个模块没有任何关系,就像两个完全独立的房间。
数据耦合(Data Coupling):
- 两个模块传递简单的数据,就像一个房间传递一个简单的消息给另一个房间。
标记耦合(Stamp Coupling):
- 两个模块传递数据结构,就像一个房间可以看到另一个房间的全部布局。
控制耦合(Control Coupling):
- 传递控制变量,一个模块控制另一个模块的行为,就像一个房间可以控制另一个房间的灯光。
外部耦合(External Coupling):
- 模块依赖于外部环境,就像一个房间依赖于外部的电力系统。
公共耦合(Common Coupling):
- 多个模块共享全局数据,就像多个房间共享同一条通道。
内容耦合(Content Coupling):
- 一个模块直接访问或修改另一个模块的内容,就像一个房间可以直接改变另一个房间的布局。
2. 设计原则
- 一个模块的 作用范围应该在其控制范围之内
- 模块的规模应该适中,而不是越小越好。因为过小的模块有可能降低模块的独立性,造成系统接口的复杂性。
3. 系统文档
- 需求分析阶段:需求规格说明书、用户用例文档、需求跟踪矩阵。
- 设计阶段:系统设计文档、数据库设计文档、界面设计文档。
- 开发阶段:代码文档、单元测试文档。
- 测试阶段:测试计划、测试用例文档、测试报告。
- 部署阶段:部署计划、配置管理文档。
- 维护阶段:维护报告、系统操作手册。
- 项目管理阶段:项目计划书、风险管理文档、项目进度报告。
4. 数据流图
- 外部实体 (External Entities): 系统外部的实体,例如人、组织或其他系统,它们与系统交互,但不是系统的一部分。
- 过程 (Processes): 表示系统内部的功能或操作,通常用圆圈或矩形表示。
- 数据流 (Data Flows): 表示信息的流动,用箭头表示,箭头的方向表示数据的流动方向。
- 数据存储 (Data Stores): 表示系统内的数据存储,例如数据库或文件,通常用两条平行线表示。
画分层数据流图(DFD)要注意的问题:
- 适当命名
- 画数据流而不是控制流
- 避免一个加工过多数据流
- 分解尽可能均匀
- 先考虑确定状态,忽略琐碎细节
- 随时准备重画
5. 数据字典
为数据流图中的每个数据流、文件、加工,以及组成数据流或文件的数据项做出说明。其中,对加工的描述称为“小说明”,也可以称为“加工逻辑说明”。
条目:数据流、数据项、数据存储和基本加工。
加工逻辑也称为“小说明”。常用的加工逻辑描述方法有结构化语言、判定表和判定树 3种。
加工规格说明不必描述实现加工的具体流程**
知识产权
Fri Nov 3 00:54, 2023
TODO: 有时间做题(未做题)
软件著作权:
- 权利自软件开发完成之日起产生。
- 客体包括计算机程序(源程序和目标程序)和相关文档(通常指软件文档)。
职务作品:
- 是为完成公司任务而开发的软件作品。
- 任职者只享有署名权,其它著作权归公司所有。
委托开发:
- 著作权归属依据合同约定,无约定时归受委托方所有。
算法
分治法 (Divide and Conquer):
- 将复杂问题分解为若干个相似但规模较小的子问题,独立解决子问题后,再合并结果解决原问题。
动态规划 (Dynamic Programming):
- 通过把原问题分解为相互重叠的子问题来工作,通过存储子问题的结果,避免重复计算。
回溯法 (Backtracking):
- 系统地搜索问题的解决方案空间,通过尝试可能的解决方案并在无法继续时回溯,找到所有解或最优解。
下午题
- 5 题,每题 15 分
推荐复习顺序:1,2,3,5/6,4
数据流图
DFD ( Data Flow Diagram )
常考题型
- 实体 E1 - E? 名称
- 数据存储 D1 - D? 名称
- 补全/修改/查找 缺失/错误 的数据流
关键概念
E: External Entity
例:人员,部门,职位,系统
D: Data Store
一般为 XX 表,想不出来的就是:输入的信息 + 表
例:表,文件。
如: 采购清单记录表,客户信息表, 学生成绩表
P: Process
例: 执行的操作
如:交易信息查询,信用卡激活,信用卡申请
⚠️ 注意
- 写数据流的时候要使用图中 未知的代号
- 查找数据流的时候先根据文字一条一条对下来,之后再根据其他进行信息进行核对
UML
统一建模语言,Unified Modeling Language
常考题型
关键概念
重复度
多重度 描述 0..1 最多1个实例。 1 必须有1个实例。 0..* 0或多个实例。 1..* 至少1个实例,可能有多个。 n 恰好n个实例。 m..n 介于m和n之间的实例数(包括m和n)。 用例 (User Case) -> 功能(类似函数名,描述了做什么)
通常使用椭圆表示
参与者(Actor)-> 人/系统/硬件
事件流
- 触发器(Trigger):开始事件流的事件或条件。
- 基本事件流(Basic Flow):描述主要路径或正常情况下的事件序列。
- 备选事件流(Alternate Flow):描述基本流程之外的其他路径。这可能是因为某些条件、异常或特殊要求。
- 异常事件流(Exception Flow):描述当出现错误或异常情况时的事件序列。
例如:“用户登录系统”用例:
触发器:用户选择“登录”按钮。
基本事件流:
- 系统提示用户输入用户名和密码。
- 用户输入用户名和密码。
- 系统验证用户输入。
- 系统通知用户登录成功,并展示主界面。
备选事件流: 1A. 用户忘记密码。
- 系统提供“忘记密码?”选项。
- 用户选择该选项并跟随指引恢复密码。
异常事件流: 3A. 输入的用户名或密码不正确。
- 系统通知用户输入的信息不正确。
- 提示用户重新输入。
⚠️ 注意
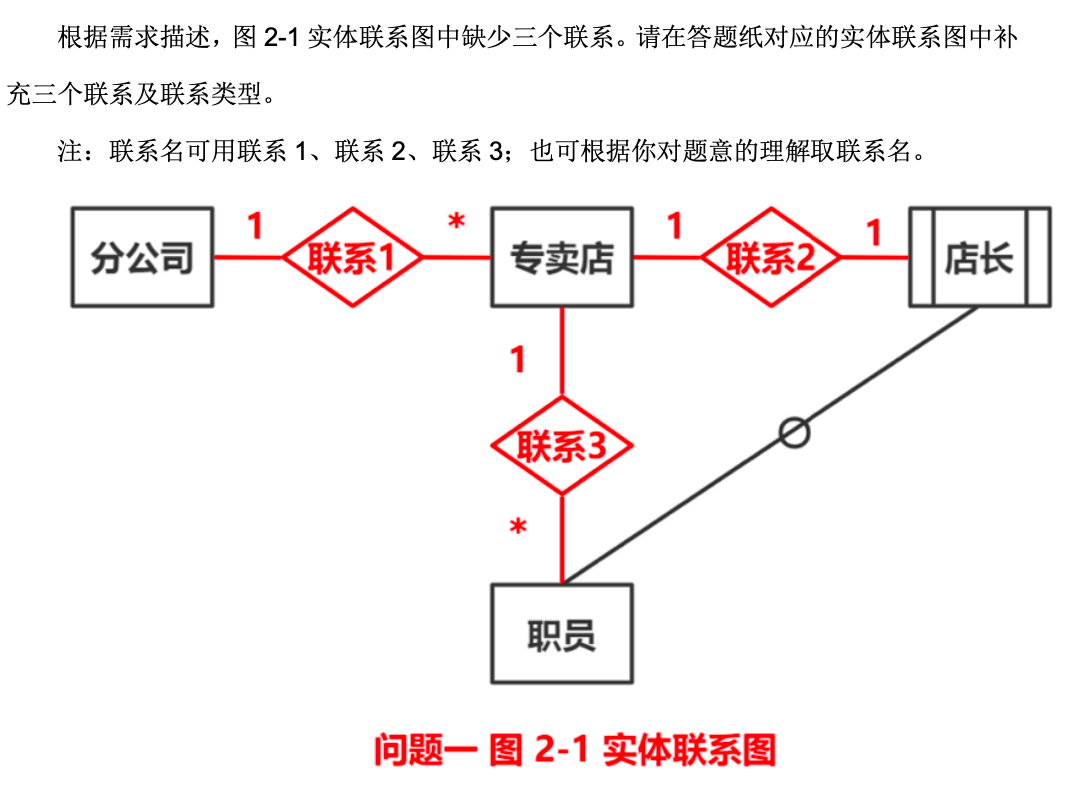

- 主键 (Primary Key):
- 主键是一个特殊的标记,帮助我们在表中快速找到特定的数据行。
- 比如,每个人的身份证号是唯一的,所以在一个人员表里,身份证号可以作为主键。
- 外键 (Foreign Key):
- 外键是一个表中的字段,它是另一个表的主键的引用。
- 比如,在一个订单表里,我们可能有一个“客户ID”字段,它指向客户表里的某个客户。在这里,“客户ID”是订单表的外键。
简单来说,主键帮助我们在表中唯一标识每一行,而外键帮助我们在不同的表之间建立联系。
面向对象
C 语言(经典算法的实现)
关键概念
时间复杂度
算法最低效时
空间复杂度
- 分治法 (Divide and Conquer):
- 分治法将原问题分解成两个或更多个相同或相似的子问题,然后递归解决子问题,最后合并这些子问题的解以得到原问题的解。
- 在这个例子中,我们可以将问题分解为几个子问题,例如,求解n-1、n-3和n-4的最优解,然后将结果合并。
- 动态规划 (Dynamic Programming):
- 动态规划与分治法类似,但是会保存子问题的解,以便在将来可以重用,而不是重新计算,从而节省计算时间。
- 在这个例子中,我们可以创建一个数组,其中索引i表示金额i的最优解。我们可以从1开始,计算每个金额的最优解,并保存在数组中供以后使用。
- 回溯 (Backtracking):
- 回溯是一种试探性的解决方案,如果当前解决方案不能完成,则撤销最后的步骤并尝试其他选项。
- 在这个例子中,我们可以从金额n开始,尝试每种硬币,如果它不导致解决方案,我们就撤销这个选择并尝试其他硬币。
Java(面向对象)
关键字
class: 一个定义了对象结构和行为的模板。对象是类的实例。interface: 一个纯抽象类,它定义了一组方法,但不提供实现。任何实现接口的类必须实现其所有方法。abstract: 用于声明抽象类或方法。抽象类不能被实例化,抽象方法必须在子类中被实现。extands :继承是一个 "is-a" 关系。例如,如果有一个基类
Animal和一个派生类Dog,那么Dog继承Animal表示 "Dog is an Animal"。implements :实现是一个 "can-do" 关系。例如,如果有一个接口
Flyable,那么任何实现了Flyable的类(如Bird或Airplane)都会表明它们可以飞行,即 "Bird can fly" 或 "Airplane can fly"。
过滤查询
关键路径:耗时最久的路径
其他
McCabe 方法计算程序的复杂度,首先需要确定流程图中的环路数。该流程图中有 3 个环路,因此程序的复杂度为 3+1=4。
改善性维护是指对软件系统进行改进,以提高其质量、效率、易用性、可维护性等方面的特
征,使其满足用户或市场的不断变化的需求。
改正性维护(A)是指修复软件系统中已知的问题或缺陷;
适应性维护(B)是指对软件系统进行适应性修改,以适应变化的环境、硬件、操作系统等;
预防性维护(D)是指在软件系统还没有发生实际问题之前,对可能发生问题的代码进行被
动或主动的检查和改进,以预防未来可能出现的问题。
短路计算是指在布尔运算中,只要能够确定整个表达式的值,就不再继续计算。

在哈夫曼编码中,频率较高的字符被分配较短的码字,而频率较低的字符被分配较长的码字,从而实现数据的高效压缩。哈夫曼编码树是一种完全二叉树,它的构建基于字符的频率。
哈夫曼编码的重要性质是前缀无歧义性,也就是说,任何字符的编码都不是其他字符编码的前缀。这个属性确保了编码的唯一解释性。